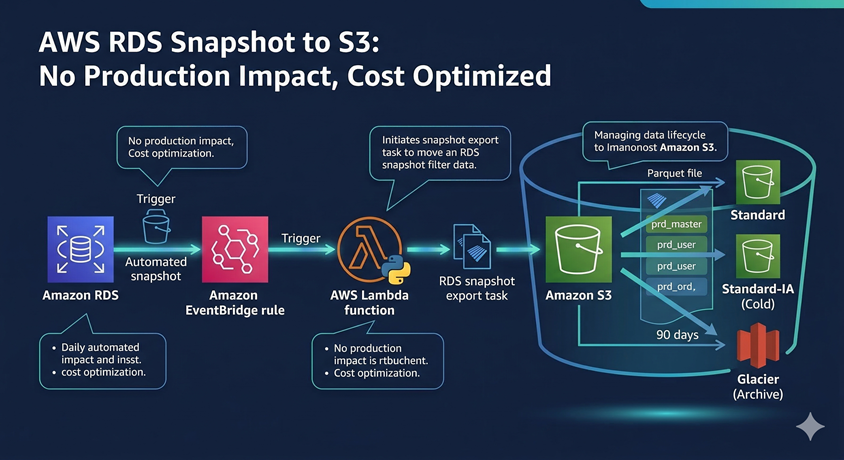
RDS(リレーショナルデータベース)のデータを分析基盤(データレイク)に連携したい時、本番DBにクエリを投げて負荷をかけたり、わざわざETLツールを導入したりして消耗していませんか?
本記事では、「RDSの自動スナップショット」を利用し、本番DBに一切の負荷をかけずにS3へのデータ連携を自動化する手法を解説します。
AWS EventBridgeとLambdaを組み合わせた完全サーバーレスなアーキテクチャで、すぐに手元で試せるIaC(Terraform)の構築コード一式はGitHubにて公開しています。
1. 全体アーキテクチャと最大のメリット
今回構築するアーキテクチャは以下の通りです。
- Amazon RDS: 日次の自動バックアップ(スナップショット)を作成。
- Amazon EventBridge: スナップショットの「作成完了」イベントを検知。
- AWS Lambda (Python): イベントを受け取り、S3へのエクスポートタスクを開始。
- Amazon S3: 抽出されたデータを保存し、ライフサイクルルールでコールド/アーカイブ層へ自動移行。
💡 最大のメリット:本番環境への影響ゼロ 稼働中のDBにSelectクエリを投げて抽出するとパフォーマンス低下のリスクが伴いますが、スナップショットからのS3エクスポート機能を使えば、AWSのバックグラウンドでデータがParquet形式に変換・出力されます。本番DBのリソースを一切消費せずにデータレイク層を構築できます。
2. Lambda(Python)の実装ポイント
① スキーマを指定して必要なデータだけを抽出する
分析に必要な特定のスキーマだけを抽出対象にしたい場合は、Boto3の start_export_task 実行時に ExportOnly パラメータを使用します。これにより、不要なログテーブルなどを省き、指定した対象のみをS3へ出力させることができます。
Python
# エクスポートするスキーマを限定する
export_only = [
"prd_master",
"prd_user",
"prd_system"
]
rds_client.start_export_task(
ExportTaskIdentifier=export_identifier,
SourceArn=event["detail"]['SourceArn'],
S3BucketName=s3_bucket_name,
IamRoleArn=os.environ.get('execution_iam_role_arn'),
KmsKeyId=os.environ.get('kms_key_id'),
S3Prefix=s3_prefix,
ExportOnly=export_only
)
② タイムゾーン(JST)の明示的な変換
Lambdaの実行環境は「UTC」です。S3のフォルダ名に日本の日付を使いたい場合、zoneinfo でJSTへ変換しないと、朝方のバックアップが前日の日付フォルダに保存される罠にハマります。
Python
from zoneinfo import ZoneInfo
from datetime import datetime as dt
jst_now = dt.now(ZoneInfo("Asia/Tokyo"))
s3_prefix = f"inbox/{db_name}/{jst_now.strftime('%Y%m%d')}"
3. 実行に必要なIAM権限と、S3運用における「落とし穴」
この仕組みをAWS上で動かす際、最もつまずきやすいのが「権限(IAM)」と「S3のコスト管理」です。
🚨 ここがハマり所! iam:PassRole の罠
Lambda関数を実行する際、単に「RDSの操作権限(rds:StartExportTask)」を持っているだけではエラーになります。 エクスポート処理はAWSの裏側で行われるため、**「RDSサービス自身がS3に書き込むためのロール(権限)」をLambdaから渡してあげる(PassRoleする)**必要があります。
Lambdaの実行ロールには、以下のポリシーが必須です。
JSON
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::123456789012:role/rds-s3-export-role"
}
💡 ストレージコストを最適化するライフサイクル設定
毎日スナップショットのデータをS3に蓄積し続けると、あっという間にストレージ料金が膨れ上がります。これを防ぐため、一定期間が過ぎたデータを安価なストレージへ自動移行する設定が不可欠です。
Terraform
# Terraformでのライフサイクル設定例
resource "aws_s3_bucket_lifecycle_configuration" "rds_export_lifecycle" {
bucket = aws_s3_bucket.rds_export_bucket.id
rule {
id = "transition-to-cold-and-archive"
status = "Enabled"
transition {
days = 30
storage_class = "STANDARD_IA" # コールドストレージへ移行
}
transition {
days = 90
storage_class = "GLACIER" # アーカイブストレージへ移行
}
}
}
🚨 【要注意】小容量ファイルはコールドストレージに移行できない?
ここでS3運用の重大な注意点です。 Standard-IA(コールド層)などのストレージクラスには、「最小オブジェクトサイズ(128KB)」の制限があります。
抽出したテーブルのデータ(Parquetファイル)が128KB未満の小さいファイルだった場合、ライフサイクルの移行対象にならない、もしくは128KBとして課金されて逆に高くつくという現象が発生します。 マスターデータなど、サイズが極端に小さいテーブルを多数エクスポートする場合は、この仕様を理解した上でストレージクラスの設計を行ってください。
4. まとめ
今回は、RDSの自動スナップショットを活用して、本番環境に一切の負荷をかけずにS3データレイクを構築する手法を解説しました。
「必要なスキーマだけを抽出」「古いデータはアーカイブ層へ移行」という実運用に即した設定を組み込むことで、クラウドの維持費も最小限に抑えることができます。 データ連携のバッチ処理やフルエクスポートの運用に課題を感じている方は、ぜひ今回のサーバーレス基盤を試してみてください!

コメント